Pwn 学习:Stack Based Overflows 实战
自己第一次学汇编是一年多以前了,逆向也搞过不少,但是 pwn 一直没尝试过。越狱 iPhone 时看了看那些漏洞的 POC 第一眼就觉得好高深啊,这起码得学完操作系统以后再说了。然而逆 iOS App 的时候学 arm 汇编看的这篇文章写了这段话:
Just think about the great tutorials on Intel x86 Exploit writing by Fuzzy Security or the Corelan Team – Guidelines like these help people interested in this specific area to get practical knowledge and the inspiration to learn beyond what is covered in those tutorials.
Well... Why not try it out? 于是就开始看。Fuzzy 的看上去有点晦涩,所以就跟着 Corelan 的走了。难易程度可以说还挺适合我。感觉 prerequisite 基本上就是学过 C 以及了解过汇编(反正遇到不会的查就得了),会某种脚本语言的话就更方便。
下面基本上记录一下我自己的复现过程。
首先准备环境。我的环境:
en_windows_xp_professional_with_service_pack_3_x86_cd_vl_x14-73974在 VMware 虚拟机里跑的。ImmunityDebugger_1_85_setupImmunity Debugger707414955696c57b71c7f160c720bed5-EasyRMtoMP3Converterexploit-db 下载mona.py右键另存为下载devcpp-4.9.9.2_setupSourceForge 下载(惊叹,这玩意真小啊)
第一步是简单验证一下漏洞,原文用 perl 写文件,因为装 Immunity Debugger 时自动装了 Python 2.7.1 所以我就直接写 Python 了。
1 | f = open('crash.m3u', 'w') |
装好 EasyRMtoMP3Converter 后导入发现直接崩溃。
然后第二步是写个小 demo 演示漏洞原理,代码
1 |
|
用 Dev-C++ 自带 gcc 编译,注意加 -g 选项生成 debug symbols.
1 | Microsoft Windows XP [Version 5.1.2600] |
编译完成后打开 Immunity Debugger 然后打开 exe 并且 arguments 随便填个 AAAAAA。进去以后单步调试观察函数调用和 strcpy 的作用。
这里正好学习一下 gdb 用法。我看的是官方手册 Debugging with GDB. 下面用 gdb 调试:
1 | C:\>gdb stacktest.exe |
break main 会在 main 函数的 prologue 后下断点,也即 0x4012d5,所以重点观察的就是这几行:
1 | 0x4012da <main+42>: mov eax,DWORD PTR [ebp+12] |
前面三行在取栈上 argv[1] 的值并放入 eax. 第 4 行将 eax 入栈。第 5 行将 eip 入栈保存 caller 地址然后跳转到 0x401290.
验证一下:
1 | (gdb) break *main+50 |
现在来看看 strcpy 的影响,在 vulnerable_func 结尾下断点,观察栈:
1 | (gdb) disassemble |
0x41 是 A 对应的 ASCII 码。可以发现 0x22fed0 - 0x22fed7 存了我们输入的参数。如果这个参数长度足够长且中间不包含 0x00,就能够覆盖后面的内存。最重要的是可以覆盖 0x22ff5c 中保存的 callee 的 eip,只要能把它修改成我们想要的值,就能让程序在指令 RET 执行时跳转到我们指定的地址。
这里有个小知识盲区,Immunity Debugger 里面显示 MOV DWORD PTR SS:[ESP],EAX 这个 SS 是啥意思?有的地方写的是 DS。于是搜了一通:What does "DS:40207A" mean in assembly? 然后又找了一下 What does dword ptr mean?
第三步是把 debugger 挂到要研究的程序上观察崩溃原因。直接打开程序然后 attach 即可。
后面要找 offset 我比较直接地在栈内存那个窗口找的字符串起点……然后减一下得到 offset. 但是很奇怪的是算的不是很准而且比正确的大 10000 左右。我找的是 0xFF730 - 0xF6E55 = 35035. 后面二分找了一下最后结果是 26059.
1 | f = open('crash.m3u', 'w') |
后面跟着文章做了一次不成功的尝试,但是当时我其实 eip 覆盖的都是错的,因为没有写成小端……
1 | f = open('crash.m3u', 'w') |
第四步是从加载的 DLL 里找 jmp esp 这个指令,绕过地址中有 \x00 导致字符串中间有 terminator 的问题。我用的是 mona.py(继承了 pvefindaddr)简单看了一下文档,下载放入 PyCommands 然后 DLL 加载完成后在 Immunity Debugger 底部文本框输入
1 | !mona find -type bin -s ffe4 |
查找出的结果在 C:\Program Files\Immunity Inc\Immunity Debugger\find.txt. 打开后搜索 MSRMCcodec02.dll 发现这行
1 | 0x01acb22a (b+0x0022b22a) : ffe4 | {PAGE_READWRITE} [MSRMCcodec02.dll] ASLR: False, Rebase: True, SafeSEH: False, OS: False, v-1.0- (C:\Program Files\Easy RM to MP3 Converter\MSRMCcodec02.dll) |
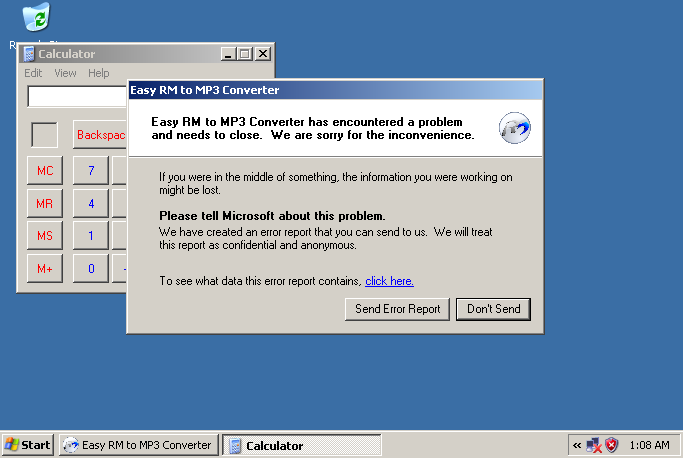
最后用了文中构造好的 shellcode 成功打开计算器
1 | f = open('crash.m3u', 'w') |
后面发现不挂载 Immunity Debugger 时打开不起作用,应该是因为 attach 在加载 DLL 前。直接打开程序然后 attach,搜索得到如下结果
1 | 0x01afb22a (b+0x0022b22a) : ffe4 | {PAGE_READWRITE} [MSRMCcodec02.dll] ASLR: False, Rebase: True, SafeSEH: False, OS: False, v-1.0- (C:\Program Files\Easy RM to MP3 Converter\MSRMCcodec02.dll) |
所以改成
1 | f = open('crash.m3u', 'w') |
最后放张成果图。